Le Principe de LoRA
À quoi sert LoRA ?
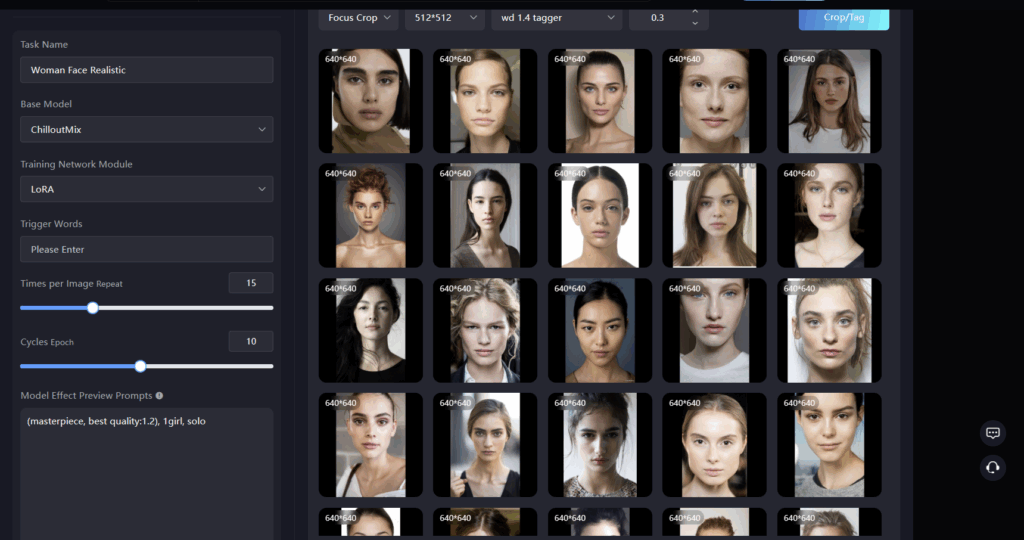
LoRA permet d’ajuster finement l’ensemble de l’image sans toucher aux poids du Checkpoint. Il suffit d’ajuster LoRA pour générer des images spécifiques.
Parfait pour les images jamais vues par l’IA → contrôlabilité accrue
Formation d’Images
Les modèles entraînés sont des affinages sur SD1.5 ou SDXL (ou sur des modèles tiers).
Formation Vidéo
L’IA génère des images → compare avec le dataset → affine les vecteurs d’embedding → rapproche les résultats du dataset.
À la fin : association parfaite entre prompt et dataset.
Comparé au Checkpoint, LoRA est plus léger, plus rapide, et ajustable par-dessus le modèle de base.

(source : SeaArt)